Table of contents
Open Table of contents
Intro to Rooflines
Typically (but not always), computation within a single chip can be overlapped with communication within a chip and between chips. This means we can lower-bound training and inference time by using the maximum of computation and communication time. We can also upper-bound with their sum. In practice, we optimize against the maximum as the algebra is simpler and we can usually come close to this bound by overlapping our communication and computation.
意思是以 这个值为衡量系统性能的理想极限,也就是下界,努力让运行时间接近这个值。 上界是 . 既然计算和通信可以同时进行,那这个任务理论上最快也要花掉两者中耗时更长的那个时间。优化代码时尽力让 computation 和 communication 是 overlapped 的。
一个比较有意思的事情是,我们一般讲 memory-bound,但是这里都用 communication-bound 代替了,是有点小巧思的。一个可能的原因是本书侧重于 scaling,而对于单卡下没有什么太大区别的 memory 和 communication 在卡与卡之间用 communication 是一个更好的称谓。LLM 对此的评价是”网络即内存“。

这个公式区分了 FLOPs 和 FLOPs/s, Communication 和 Bandwidth 的区别。上方是理论计算时间与理论通信时间,进行交叉相乘的变形后得到 算法计算强度 > 硬件机器强度 的结论。所以判断一个程序是卡在算力还是显存,和程序的计算强度是否高于这个显卡平衡点的门槛是相关的。
此处 back-of-the-envelope calculation 得到了大多数机器很难达到 compute-bound 的事实。
A Few Problems to Work 的 Question 2 问,如果用 int8 权重量化但是保持激活值和计算是 bf16,如何衡量计算限制?我们计算 ,其中 是 input activation 是动态变化的,而 是 weight 是模型训练好之后固定下来的参数,负责把 维的向量映射为 维的向量,是静态的。 是 output activation.
可以理解 是 Batch Size,那末 就是输入 个 Token 而每个 Token 变成了一个长度为 的向量,然后将 维度向量映射为 维。假设 Batch Size () 非常小,即 且 ,以 LLaMA-7B 举例,假设隐藏层维度 ,在对话推理 Generation 时每次只吐出一个词,此时 Batch Size ,可以计算得到搬运权重 和输入激活值 、输出激活值 有大约四个数量级的差距。
激活值 对应 bytes (bf16) ,权重 对应 byte (int8) ,写回 bytes(bf16) ,总访存量应该是 。对于批量较小假设得到总访存 。 得出的算数强度就是 ,若为纯 bf16 则为 。
Shared Matmuls
此处主要是理解分片矩阵的计算机制。对于 :
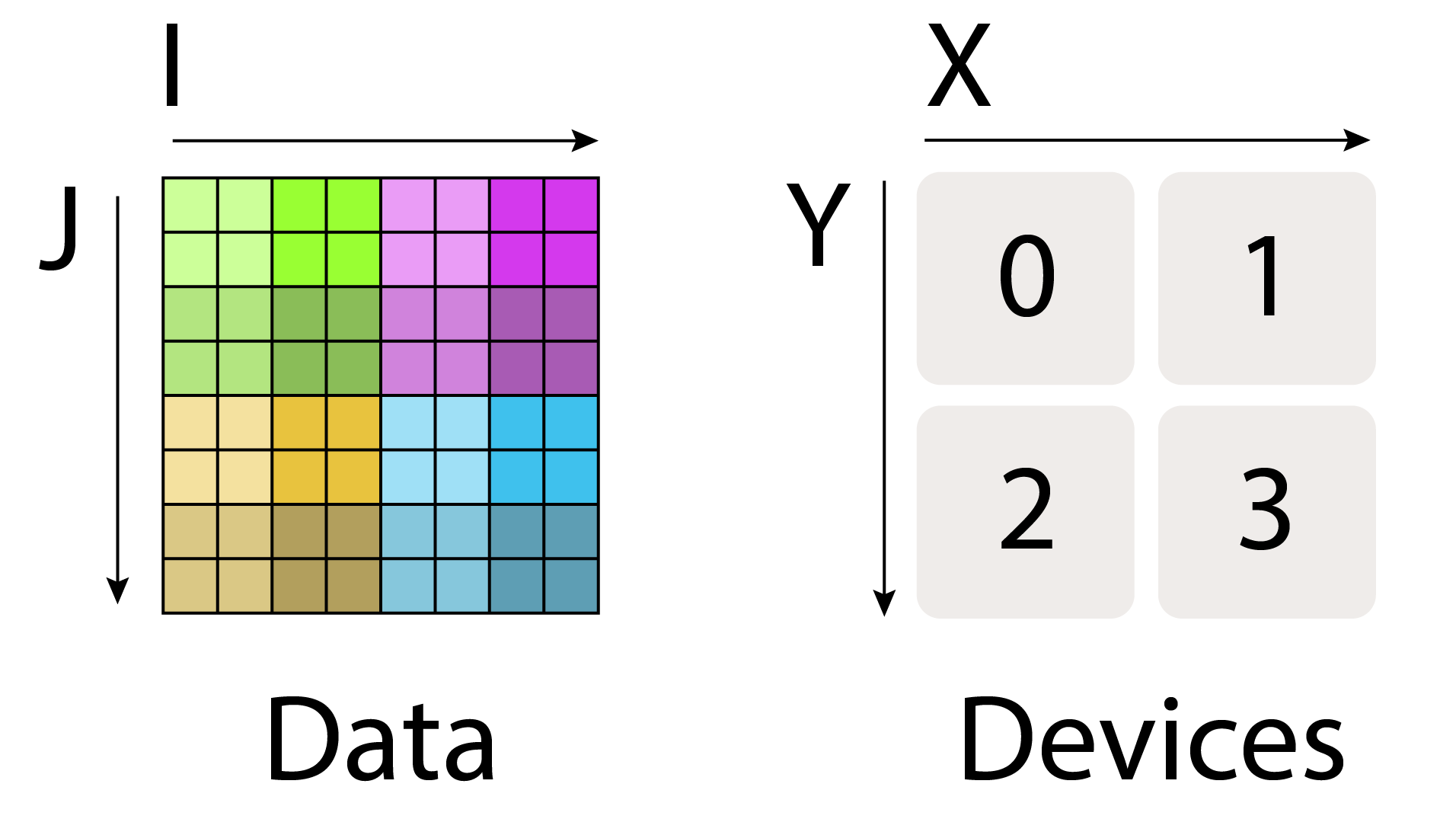
可以做 进行分区,那么在逻辑轴 上沿着 维度切开,但是 不切分。
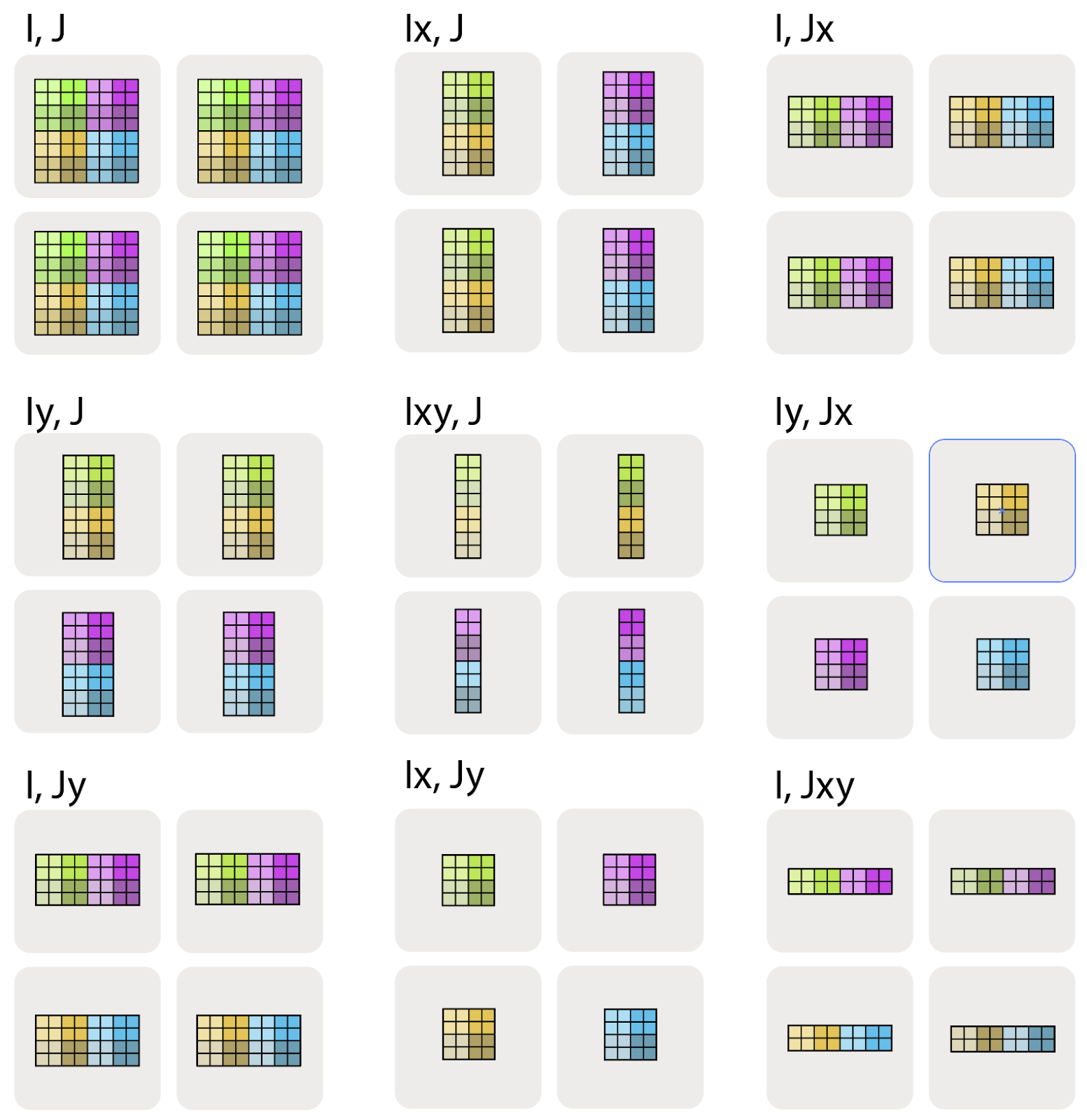
的意思是左右 () 的机器拿到不同的数据,而上下的 () 机器拿到相同的数据,也就是在 上将获得完整的副本。由此就可以理解 了,上下 () 的机器拿到不同的数据。 可以先从 上沿着 切,再从 上沿 切,我觉得把沿 和沿 理清就不会对此有太大的疑惑。
这是理解 shared dimension multiplication 的基础,对于被收缩 (sharded) 的矩阵:
通常来说,
AllGather 是一种移除沿某个轴分片的 MPI communication primitive,通过数学可以证明,类似的通信原语的通信时间都是仅取决于数组的大小 (数组字节数)和 ICI 可用带宽 ,而不取决于数组分片数量 ,公式 .
关于延迟的一些具体内容有些复杂,暂时搁置它。
上述内容讨论的是只有一个乘数的维度被分片的情况,如果是两个乘数的收缩维度被分片,
此时局部分片的矩阵乘法是可行的,我们可以这么做:
沿着 网络还未作归约,可以认为处于”未完成“状态。这可以被理解为一种外积,外积即 的每一列与 的每一行做外积,得到 个同等大小的大矩阵,把它们按位置相加,结果和常规矩阵乘法一模一样。执行这种求和也就是:
AllReduce 的执行方式可以理解为,每个设备将其分片发送给相邻设备,并对接收到的所有分片进行求和。通常 AllReduce 的成本是 AllGather 的两倍,可以认为 AllReduce 是两个原语的组合——ReduceScatter 和 AllGather。
ReduceScatter 对一个未归约/部分求和的数组进行求和,然后沿着相同的网格轴分散 (scatters or shards) 不同的逻辑轴。AllGather 重组了一个分片数组(移除下标)。AllGather 和 ReduceScatter 的通信开销是 ,AllReduce 是 .
另外 AllToAll 也是一种通信原语,沿同一轴收集(复制)一个维度,并分片另一个维度。可以写为 .
一些内容此处没有提及,在后面的篇章还会提到。此处总结一些比较贴近直觉的观点:
HBM (显存) > NVLink (机内互联) > PCIe (连接CPU) > InfiniBand / RDMA (机间互联)。比如 TP 一般在同一机器(同一 Node)的几张卡内做 AllReduce,走 NVLink。跨机器一般做 PP 或者 DP。
还有就是利用通信与计算的重叠 overlap 掩盖延迟问题。
Transformer Math
对于 shape 为 的 和 shape 同为 的 , 点积进行 次加法,为 浮点运算。对于引入矩阵的情况,可以将矩阵与向量的点积 视为加法的 次重复,矩阵矩阵乘同理。
对于矩阵乘,如果维度出现在两个输入张量中,但不在输出张量中,称为收缩维度。而批处理维度是并行独立的数据块。对于 ,举例 是多维 Batch,因为 并不在 中;收缩 ,相当于把 和 组成的 2D Grid 进行求和,也可以是单一维度 ,就像普通的二维矩阵乘法一样。
在一般的深度学习框架里用爱因斯坦求和表示乘法。另外,矩阵乘法的计算量立方级增长,但是数据传输是平方级的,所以矩阵乘法更容易达到计算饱和的极限 (compute-saturated limit).
经过数学推导,可以得到前向传播的 FLOPs 是计算 对应的 ,反向传播是更新当前层权重的 和把梯度向前一层网络传递 对应的 . 其中 是矩阵参数数量,这就是 Transformer 训练期间的 6 * num parameters * num tokens 对每个 token 的 6 * num parameters.
关于 Transformer 可以阅读 Visualizing machine learning one concept at a time,很清晰。Self-Attention 是一个纯线性的关于 V 的计算,需要引入 FFN 作为非线性部分.

FFN 和 MLP 基本可以认为是等价的,在 Transformer 和 LLM 的语境下。另外需要非常熟练掌握这个图:
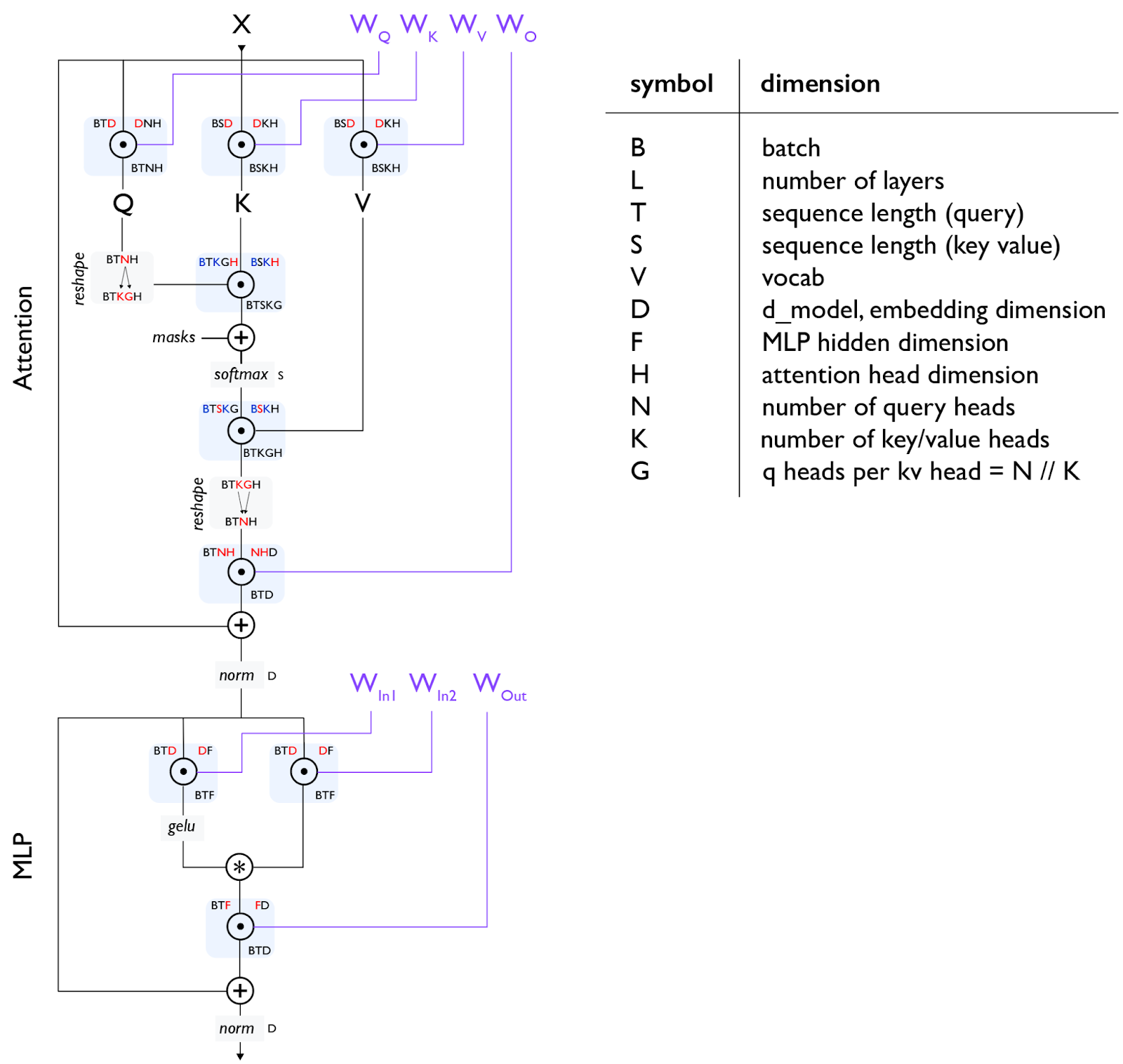
其中 在和 相乘之前 reshape 将 变换为 . LLM 为了节省显存,使用的 Key/Value head number () 小于 Query head number (),将 拆为 ,其中 为每个 KV 头共享的 Query head number. 这就是 GQA. 关于 MHA, MQA 和 GQA 可以阅读这个文章。
如果是做分布式切分,在 Attention 部分通常是 attention head number and ,如果是 MLP 部分一般是 hidden dimension . 之后 AllReduce.
此处做的是 post-norm, 和原始 Transformer 一致,表示为 norm(x + attn(x))。但是 most modern Transformers 现在在使用 pre-norm, 归一化发生在残差连接 (residual connection) 之前,表示为 x + attn(norm(x))。
讨论 train FLOPs 时,MLPs 一般有两个矩阵输入 和 ,各自 加上输出总共就是 . 注意力机制 , , , 最后计算得到 . 点积则是 ,这一部分都是数学。注意在实际实现中,因果掩码会让有效浮点运算会减少一半。
Training
model scaling 的主要目标在于,让训练或者推理过程中增加使用的芯片数量能实现成比例的线性吞吐量提升 (强扩展, strong scaling). 将讨论以下四种 parallelism schemes:
- (pure) data parallelism
- fully-sharded data parallelism (FSDP / ZeRO sharding)
- tensor parallelism (model parallelism)
- pipeline parallelism
对于 sequence length 小于 8 倍的 hidden dimension 的情况 (),MLP 模块的参数量就主导了总参数量,MLP 模块也主导了 FLOPs 预算。
今天看了一个 meme,问 FLOPS 和 FLOPs 究竟是什么意思,一般来说 FLOPS 是 算力/性能,而 FLOPs 是总计算量 (总运算次数)。所需算力 = 计算量 div 时间。有些人也会把 FLOPS 写成 FLOPs/s 这种更能避免歧义的写法。
出于简化考虑我们可以将 Transformer 近似为多层感知机 (MLP) 的堆叠:
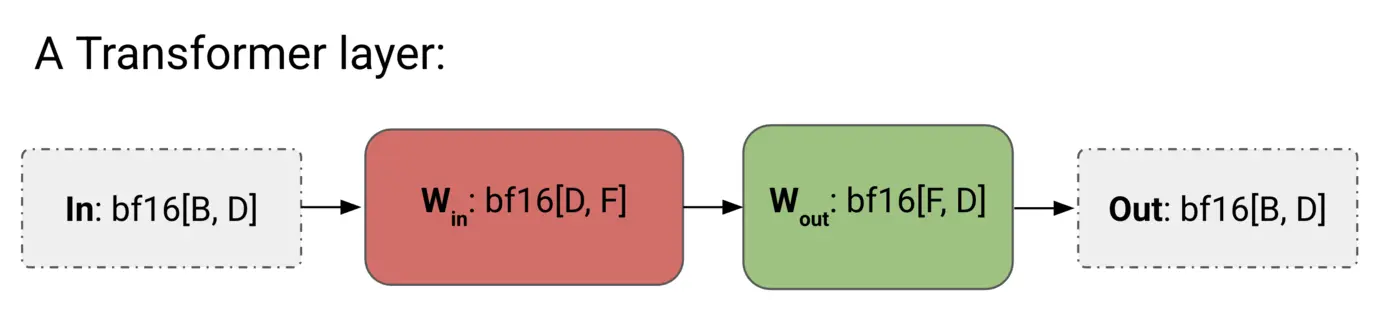
将两个前馈网络 FFW 块视为两个矩阵 和 的堆叠。